++++ UPDATE (2018): several later iterations of the text below has resulted in a ++++
++++ textbook on ontology engineering ++++
You have arrived at the start page of the course on ontologyengineering that will be held from 26-30 July 2010 at the Knowledge Representation and Reasoning Group, Meraka Institute,CSIR, Pretoria, South Africa as part of the Masters Ontology Winter School2010, and taught by Maria Keet fromthe KRDB Research Centre, Free University of Bozen-Bolzano, Italy.
Aims of the course
The principal aim of thiscourse is to provide the participant with a comprehensive overview of ontologyengineering, so that the participant will be aware of the main topics thatinfluence the development of an ontology. Due to the introductory nature, thescope is breath of the discipline, not depth. Participant with a differentbackground will obtain a sufficient general basis to delve into preferredsub-topics themselves and/or take advanced courses in such sub-topics ofontology engineering.
A secondary aim is to providehands-on experience in ontology development that illustrate the theory,including language features, reasoning, ontology reuse, and bottom-up ontologydevelopment.
Abstract
This introductory course onontology engineering for the Semantic Web covers material to understand thenotion of what ontologies are, what they can be used for, OWL to representontologies, and basic aspects to develop ontologies. Ontology developmentfocuses on the two principled approaches---top-down with Ontology andfoundational ontologies and bottom-up using non-ontological resources such asrelational databases, natural language or thesauri---and addresses some aspectsof methods and methodologies.
Depending on the background,time, and interest of the participants, an elective topic will be chosen, beingvagueness, temporal aspects, or modelling and reasoning challenges.
Housekeeping issues
- Thiscourse consists of lectures and exercises that will be carried out in smallgroups.
- Followingthe lectures and gaining the most of the course will be easier when you haveread the required reading beforehand, in particular given that the schedule istight and squeezed into one week.
- Eachlecture takes about 1.5 hours, labs 45 minutes.
- Detailsabout lab exercises and sample exam questions will be provided during thecourse.
- Slideswill be made available on this page at the end of the course (but note that they do not suffice as a neat summary of the contents). Download the course slides (14MB) or the handouts (5.5MB, 6 on 1 page)
- Itis assumed the participant is familiar with first order logic and conceptualdata modelling, such as UML and ER.
- Thetopics covered in this course are of an introductory nature and due to timeconstraints only a selection of core and elective topics will be addressed.There is a more comprehensive list of topics that can be spread out over anentire MScdegree programme.
- Thefollowing references are requiredreading: 1, 5, 12, 13, 21, 22 first part or 23, 26, 41, 44, 45 (part), 49, 50,and recommended reading: 7, 8,10, 24, 31 (part), 43, 49, 57, 60, 65; the remainder of the references areoptional reading, depending on one's interests and background knowledge.
Outline of the course
Introduction to OntologyEngineering, with emphasis on Semantic Web Technologies
1. Introduction
1.1 What is an ontology?
1.2 What is the usefulness of anontology?
1.3 Success stories
2. Ontology languages
2.1 OWL
2.3 OWL 2
3. Foundational and Top-down aspects
3.1 Foundational ontologies
3.2 Part-whole relations
3.3 Ontology Design Patterns
4. Bottom-up ontology development
4.1 Relational databases and related'legacy' KR
4.2 Natural language processing andontologies
4.3 Biological models and thesauri
5. Methods and methodologies
5.1 Design parameters and theirdependencies
5.2 Methods: OntoClean and Debugging
5.3 Methodologies and tools
6. Extra topics
6.1 Uncertainty and vagueness
6.2 Time and Temporal Ontologies
6.3 Challenges in representation andreasoning over ontologies and social aspects
Bibliography
A. Books and journals aboutontologies
B. Course References
Course Schedule
(subject to change)
| | Mo. July 26 | Tue. July 27 | Wed. July 28 | Thu. July 29 | Fri. July 30 |
| 9:00-10:30 | Introduction | Foundational ontologies, | ODPs | Thesauri | Methods & Tools |
| OWL | Part-whole relations I | Bottom-up, RDBMSs | Parameters | overflow |
| 10:30-10:45 | Break | Break | Break | Break | Break |
| 10:45-12.15 | OWL, OWL 2 | Part-whole relations II | NLP, biomodels | OntoClean & Debugging | Extra topic: challenges |
| 12:15-12:20 | Break | Break | Break | Break | Break |
| 12:20-13:00 | OWL 2, reasoning | Labs | Labs | Labs | Labs |
| | | | | | |
| | | | | | |
| | 1. Introduction | | | |
| | 2. Ontology languages | | | |
| | 3. Top-down: Foundational aspects | | |
| | 4. Bottom-up ontology development | | |
| | 5. Methods and Methodologies | | |
| | 6. Extra topic | | | | |
| | Labs | | | | |
1.1 What is an ontology?
To place an ontology engineering course in its rightcontext, the first two questions one has to ask and answer are: What is anontology? and What is it goodfor? (or: what problems does it solve?)
There is no unanimously agreed-upon definition what anontology is and proposed definitions within computer science have changed overthe past 20 years; see e.g., Guarino's landmark paperand herewithin a broader scope of the ontological leveland a more recent overview about definitions of "an ontology" versus Ontologyin philosophy that refinesin a step-wise and more precise fashion Studer et al's (1998) definition of "An ontology is a formal, explicit specification of a sharedconceptualization". For better or worse, currently and in the context ofthe Semantic Web, the tendency is toward it being equivalent to a logicaltheory, and a Description Logics knowledge base in particular—evenformalizing a thesaurus in OWL then ends up as a simple 'ontology' (e.g., the NCI thesaurus as cancerontology) and a conceptual data model originally in EER or UML becomes an'application ontology' by virtue of being formalized in OWL. Salient aspects ofthe merits of one definition and other will pass the revue during the lecture.Orthogonally, there is a debate about ontology as a representation of aconceptualization and as a representation of reality, among others. For aninitial indication of 'things that have to do with an ontology', Figure 1 showsthe 2007 Ontology Summit's "Dimensionmap" that is by its authors intended as a "Template for discourse" aboutontologies, which has a briefand longerexplanation.
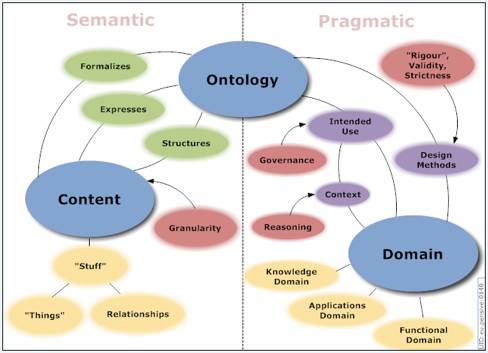
Figure 1. The OntologySummit2007's "Dimension map".
1.2 What is the usefulness of an ontology?
Ontologies for information systems were first proposed tocontribute to solving the issues with data integration by means of providing acommon vocabulary that is at one level of abstraction higher up than conceptualdata models. The orchestration of the principal components will be describedduring the lecture, given that this is still an important usage area.
Over the years, ontologies have been shown to be useful in amyriad of other application scenarios. For instance, negotiation betweensoftware services, mediation between software agents, bringing more qualitycriteria into conceptual data modelling to develop a better model (hence, abetter quality software system), orchestrating the components in semanticscientific workflows, e-learning, ontology-based data access, top-k informationretrieval, management of digital libraries, improving the accuracy of questionanswering systems, and annotation and analysis of electronic health records.
However, this does not mean that ontologies are the panaceafor everything, and some ontologies are better suitable to solve one or some ofthe problems, but not others. Put differently, it is prudent to keep one'sapproach to engineering: conduct a problem analysis first, collect therequirements and goals, and then assess if an ontology indeed is part of thesolution or not. If so, then we enter in the ontology engineering area so as tomake it work.
1.3 Success stories
To be able to talk about successes—andchallenges—of ontologies, and its incarnation with Semantic WebTechnologies in particular, one first needs to establish when something can bedeemed a success, when it is a challenge, and when it is an outright failure.Such measures can be devised in an absolute sense (compare technology x with an ontology-mediated one: does it outperform onmeasure y?) and relative (to whomis technology x deemedsuccessful?). During the lecture, we will illustrate some of the successes,whereas challenges are deferred to later on in the course.
A major success story of the development and use ofontologies for data linking and integration is the Gene Ontology[4],its offspring, and subsequent coordinated evolution of ontologies[5]within the OBO Foundry project. Thesefrontrunners from the Gene Ontology Consortium and their colleagues inbioinformatics were adopters of some of the Semantic Web ideas even beforeBerners-Lee, Hendler, and Lassila wrote their Scientific American paper in 2001[6],even though they did not formulate their needs and intentions in the sameterminology: they did want to have shared, controlled vocabularies with thesame syntax, to facilitate data integration—or at leastinteroperability—across Web-accessible databases, have a common space foridentifiers, it needing to be a dynamic, changing system, to organize and queryincomplete biological knowledge, and, albeit not stated explicitly, it allstill needed to be highly scalable [4]. That is, bioinformaticians anddomain experts in genomics already organized themselves together in the Gene Ontology Consortium, which was setup officially in 1998 to realize a solution for these requirements. The resultsexceeded anyone's expectations in its success for a range of reasons. Manytools for the Gene Ontology (GO) and its common KR format, .obo, have beendeveloped, and other research groups adopted the approach to develop controlledvocabularies either by extending the GO, e.g., rice traits, or adding their ownsubject domain, such as zebrafish anatomy and mouse developmental stages. Thisproliferation, as well as the OWL development and standardization process thatwas going on at about the same time, pushed the goal posts further: newexpectations were put on the GO and its siblings and on their tools, and theproliferation had become a bit too wieldy to keep a good overview what wasgoing on and how those ontologies would be put together. Put differently, somepeople noticed the inferencing possibilities that can be obtained from movingfrom obo to OWL and others thought that some coordination among all those obobio-ontologies would be advantageous given that post-hoc integration ofontologies of related and overlapping subject domains is not easy. Thus cameinto being the OBO Foundry to solvesuch issues, proposing a methodology for coordinated evolution of ontologies tosupport biomedical data integration .
People in related disciplines, such as ecology, have takenon board experiences of these very early adopters, and instead decided to jumpon board after the OWL standardization. They, however, were not only motivatedby data(base) integration. Referring to Madin et al's paper,I highlight three points they made: "terminological ambiguity slows scientificprogress, leads to redundant research efforts, and ultimately impedes advancestowards a unified foundation for ecological science", i.e., identification ofsome serious problems they have in ecological research; "Formal ontologiesprovide a mechanism to address the drawbacks of terminological ambiguity inecology", i.e., what they expect that ontologies will solve for them(disambiguation); and "and fill an important gap in the management ofecological data by facilitating powerful data discovery based on rigorously defined,scientifically meaningful terms", i.e., for what purpose they want to useontologies and any associated computation (discovery using automatedreasoning). That is, ontologies not as a—one of many possible—toolin the engineering infrastructure, but as arequired part of a method in the scientific investigation that aims todiscover new information and knowledge about nature (i.e., in answering thewho, what, where, when, and how things are the way they are in nature).
Success in inferring novel biological knowledge has beenachieved with classification of protein phosphatases,precisely thanks to the expressive ontology and its reasoning services.
Yet a different usage is to link ontologies to data[9]in such a way that is still scalable to GBs of data. This has been madeend-user usable through a Web-based interfaceso that the domain experts can formulate their desired queries at the'what'-layer (concepts and relations in the ontology) instead of the'how'-layer, thereby solving issues such as having to learn SQL (or SPARQL),knowing the structure of how the data is stored, and inflexibility of cannedqueries.
Although perhapsmore foundations in ontologies is useful before delving into how to representwhat you want to represent, having a basic grasp of logic-based ontologylanguages also can help understanding the ontologies and ontology engineeringbetter. Therefore, we shall refresh the basics of first order logic(comprehensive introductions can be found elsewhere[11]) and subsequently we will look at themotivations for and features of the Web Ontology Languages OWL and OWL 2. Toput the OWL languages in their right location in the prominent technologicalinfrastructure for deploying ontologies, the Semantic Web, you can have a lookat the common layer cake picture in Figure 2 (for the beginner in 'modellingknowledge', there is also an OWL primer and for an introductory rationale for a Semantic Web and its technologies, Lee Feigenbaum's slides about the "Semantic Web Landscape" may be of interest).
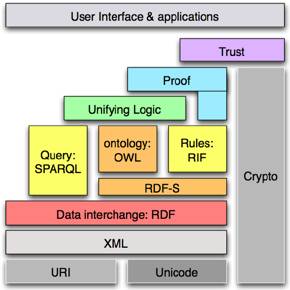
Figure 2. TheSemantic Web layer cake.
2.1 OWL
Before OWL, therewere a plethora of ontology languages, such the obo format (directed acyclicgraphs) mentioned in the previous section, KL-ONE, and F-logic (frames, andolder versions of the Protégé ontology development tool), which,unsurprisingly, causes ontology interoperation problems even on the syntacticlevel. Within the Semantic Web layer cake, it appeared that RDFS had someproblems to function as ontology language—expressive limitations,syntactic and semantic issues—which is what OWL aimed to address so as toprovide a comprehensive ontology language for the Semantic Web. In addition tothe RDFS issues, several predecessors to OWL had a considerable influence onthe final product, most notably SHOE, DAML-ONT, OIL, and DAML+OIL, and, moregenerally, the fruits of 20 years of research on languages and prototyping ofautomated reasoners by the Description Logics (DL) community. What makes OWL aSemantic Web language compared to the regular DL languages, is that OWL usesURI references as names (like used in RDF, e.g., http://www.w3.org/2002/07/owl#Thing),it gathers information into ontologies stored as documents written in RDF/XMLincluding things like owl:imports, and it adds RDF datatypes and XML schema data types for the ranges of data properties (attributes).
In addition, therewas a document of requirements and objectives that such an ontology langue forthe Semantic Web should meet, which we shall address during the lecture. The "making of an ontology language"article[12] gives a general historical view and summaryof OWL with its three species (OWL lite, OWL-DL, and OWL full) and the detailsof the standard can be found here, which will be summarized in the lecture.The article does not give you a clear definition of what an ontology is (otherthan a DL knowledge base), but instead gives some directions on they purposesit can be used for.
Over the past 5years, OWL has been used across subject domains, but in particular in the heathcare and life sciences disciplines, perhaps also thanks to the W3C interestgroup dedicated to this topic (the HCLSIG). Experimentation with the standard, however,revealed expected as well as unexpected shortcomings in addition to the ideasmentioned in the "Future extensions" section of so that a successor to OWL was deemed to be ofvalue. Work towards a standardization of an OWL 2 took shape after the OWLExperiences and Directions workshop in 2007 and a final draft was ready by late2008. On October 27 2009 it has become the official OWL 2 W3C recommendation.
2.3 OWL 2
What does this OWL2 consists of, and what does it fix? The language aims to address (to a greateror lesser extent) the issues described in section 2 of, which is not quite a super- or subset of
's ideas for possible extensions. For instance, the consideration tocater for the Unique Name Assumption did not make it into OWL 2, despite thatit has quite an effect on the complexity of a language.
First, you can seethe 'orchestration' of the various aspects of OWL 2 in Figure 3 below. The topsection indicates several syntaxes that can be used to serialize the ontology,with RDF/XML being required and the other four optional. Then there are mappings between an OWL ontology and RDF graphin the middle, and the lower half depicts that there is both a direct semantics ("OWL 2 DL") and an RDF-based one ("OWL 2 full").
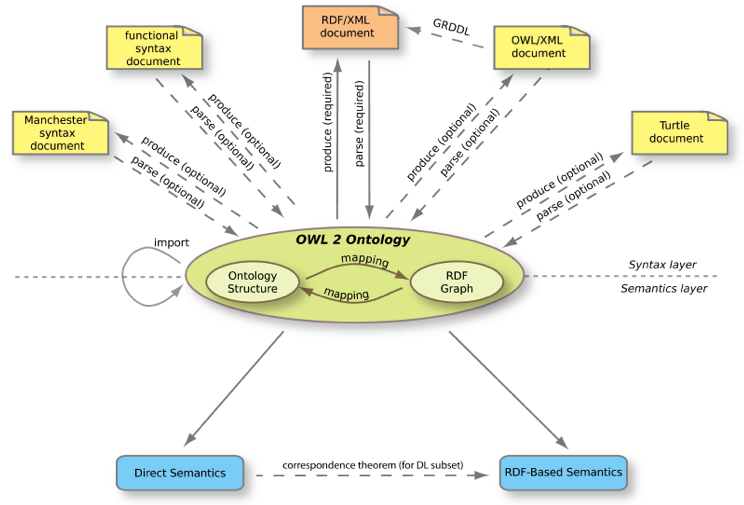
Figure 3.Orchestration of syntax and semantics of OWL 2 (source).
Second, the OWL 2DL species is based on the DL language called SROIQ(D), which is more expressive than the baselanguage of OWL-DL (SHOIN(D)) and therewith meeting some of the ontologymodellers' requests, such as more properties of properties and qualified numberrestrictions. Then there is cleaner support for annotations, debatable (from anontological perspective, that is) punning for metamodelling, and a deceptive'key' functionality that is not a key in the common and traditional sense ofkeys in conceptual models and databases. Also, it irons out some difficultiesthat tool implementers had with the syntaxes of OWL and makes importingontologies more transparent. To name but a few things.
Third, in additionto the OWL 2 DL version, there are three OWL2 profiles, which are, strictly speaking,sub-languages of (syntactic restrictions on) OWL 2 DL so as to cater fordifferent purposes of ontology usage in applications. This choice has itsconsequences that very well can, but may not necessarily, turn out to be apositive one; we shall dwell on this point in the part on ontology engineeringmethodologies. The three profiles are OWL 2 EL that is based on the EL++language[16], OWL 2 QL that is based on the DL-LiteRlanguage[17], and OWL 2 RL[18] that is inspired by Description LogicPrograms and pD[19], which are intended for use with largerelatively simple type-level ontologies, querying large amounts of instancesthrough the ontology, and ontologies with rules and data in the form of RDFtriples, respectively. Like with OWL 2 DL, each of these languages hasautomated reasoners tailored to the language so as to achieve the bestperformance for the application scenario. Indirectly, the notion of theprofiles and automated reasoners says you cannot have it all together in onelanguage and expect to have good performance with your ontology andontology-driven information system. Such is life with the limitations ofcomputers (why this is so, is taught in a theory of computing course), but onecan achieve quite impressive results with the languages and its tools that arepractically not really doable with paper-based manual efforts or OWL 2 DL. Ifyou are a novice in computational complexity, you may want to consult aninformal explanation of trade-offs between ontology languages and languagefeatures[20].
During this secondsection of the lecture, we discuss the OWL 2 features and profiles morecomprehensively and provide context to the rationale how and why things endedup the way they did.
3. Foundational and Top-downaspects
Having an ontology language is one thing, but what to represent, and how, is quite another. Where do you start? How can youavoid reinventing the wheel? What things can guide you to make the processeasier to carry it out successfully? How can you make the best of 'legacy'material? There are two principal approaches, being the so-called top-down and bottom-up ontology development; in this section, we focus on the former and inthe next section on the latter.
3.1 Foundational ontologies
The basic starting point for top-down ontology developmentis to think of, and decide about, core principles. For instance, do you committo a 3D view with objects persisting in time or a perdurantist one withspace-time worms, are you concerned with (in OWL terminology) classes orindividuals, is your ontology intended to be descriptive or prescriptive (see,e.g. beyond concepts,the WonderWeb deliverable,and a synopsis of the main design decisions for DOLCE[23])?Practically, the different answers to such questions end up as different foundationalontologies—even with the same answersthey may be different. Foundational ontologies provide a high-levelcategorization about the kinds of things you will model, such as process, non-agentive-physical-object, and (what are and) how to represent 'attributes'such as Colour and Height (e.g., as qualities or some kind of dependent continuant or trope.).
There are several such foundational ontologies, such as DOLCE, BFO, GFO, natural language focusedGUM,and SUMO. Within the Wonderweb project, theparticipants realized it might not be feasible to have one single foundationalontology that pleases everybody; hence, the idea was to have a library offoundational ontologies with appropriate mappings between them so that eachmodeller can choose his or her pet ontology and the system will sort out therest regarding the interoperability of ontologies that use differentfoundational ontologies. The basis for this has been laid with the Wonderwebdeliverable D18, but an implementation is yet to be done. One of thehurdles to realize this, is that people who tend to be interested infoundational ontologies start out formalizing the basic categories in a logicof their convenience (which is not OWL). For instance, DOLCE—theDescriptive Ontology for Linguistic and Cognitive Engineering—has apaper-based formalisation in a first order predicate logic, and subsequenttrimming down in lite and ultralite OWL versions. BFO—the Basic FormalOntology—, too, has a version of it in first order logic in Isabellesyntax.
In the meantime, leaner OWL versions of DOLCE and BFO havebeen made available, which are intended to be used for development ofontologies in one's domain of interest. These files can be found on theirrespective websites at the LOAand IFOMIS. To read them leisurely andmake a comparison—and finding any correspondence—of the twofoundational ontologies somewhat easier, I have exported the DOLCE-liteand BFO 1.1 OWL versions in a Description Logics representation and Manchestersyntax rendering (generated with the Protégé 4.0 ontology developmenttool). Whereas DOLCE-Lite is encoded in the DL language that is characterizedby SHI, BFO is simpler (in ALC); that is, neither one uses all OWL-DL capabilitiesof SHOIN(D). Another differenceis that BFO-in-owl is only a bare taxonomy (extensions do exist though),whereas DOLCE-Lite makes heavy use of object properties. More aspects of bothfoundational ontologies will be addressed in the lecture.
DOLCE contains several relations it deems necessary for afoundational ontology. BFO, on the other hand, has a taxonomy, a separatetheory of parthood relations, and an extension including the Relation Ontology.The Relation Ontologywas developed to assist ontology developers in avoiding errors in modelling andassist users in using the ontology for annotations, and such that severalontologies would use the same set of agreed-upon defined relations to fosterinteroperability among the ontologies. Philosophically, it is still a debatewhat then the 'essential' relations are to represent reality, and if thoseincluded are good enough, are too many or too few. Currently, several extensions to theRO are under consideration and refinements have been proposed, such as forRO's transformation_ofthat avails of theory underlying OntoClean (that we address in a later lecture)and the derived_from relation.
3.2 Part-whole relations
A, if not the,essential relation is the part-whole relation. Aside from workarounds mentionedin the SemanticWeb best practices document about part-whole relations and further confusion by OWL developers
, part-whole relations are deemed essential by the most activeadopters of ontologies—i.e., bio- and medical scientist—while itsfull potential is yet to be discovered by, among others, manufacturing. A fewobvious examples are how to represent plant or animal anatomy, geographicinformation data, and components of devices. And then the need to reason overit. For instance, when we can deduce which part of the device is broken, thenonly that part has to be replaced instead of the whole it is part of (saving acompany money), and one may want to deduce that when I have an injury in myankle, I have an injury in my limb, but not deduce that if you have anamputation of your toe, you also have an amputation of your foot that the toeis (well, was) part of. If a toddler swallowed a Lego brick, it is spatially containedin his stomach, but one does not deduce itis structurally part of hisstomach (normally it will leave the body unchanged through the usual channel).This toddler-with-lego-brick gives a clue why, from an ontological perspective, equation 23 in isincorrect (in addition to being prohibited by OWL 2 DL anyway).
To shed light on part-whole relations and sort out suchmodelling problems, we will look first at mereology (the Ontology take onpart-whole relations), and to a lesser extent meronymy (from linguistics), andsubsequently structure the different terms that are perceived to have somethingto do with part-whole relations into a taxonomy of part-whole relations[26].This, in turn, is to be put to use, be it with manual or software-supportedguidelines to choose the most appropriate part-whole relation for the problem,and subsequently to make sure that is indeed represented correctly in anontology. The latter can be done by availing of the so-called RBox ReasoningService. All this will not solve eachmodelling problem of part-whole relations, but at least provide you with asound basis.
Various extensions to mereology are being investigated, suchas mereotopology, the notion of essential parthood[27],and mereogeometry. We shall touch upon basic aspects for mereotopology; theinterested reader may want to consult, among others, ontological foundations[28],the introduction of the RCC8 spatial relations,and exploration toward integrating RCC8 with OWL.
3.3 Ontology Design Patterns
A different approach to the reuse of principal notions, isto use ontology design patterns (ODPs),which is inspired by the idea of software design patterns. Basically, ODPsprovide mini-ontologies with formalised knowledge for how to go about modellingreusable pieces, e.g. an n-ary relation or a relation between data type values,in an ontology (in OWL-DL), so that one can do that consistently throughout theontology development and across ontologies. ODPs for specific subject domainsare called content ODPs, such asthe 'sales and purchase order contracts' or the 'agent role' to representagents, the roles they play, and the relations between them, and even anattempt to consistently represent the classification scheme invented byLinnaeus with an ODP.
There are several different types of ODPs, which aresummarized in Figure 4, which was taken from the rather comprehensivedeliverable about ODPs.
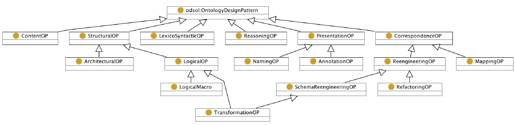
Figure 4. Categorisation of types of ontology designpatterns.
Other foundational ontology aspects, such as philosophy oflanguage, modal logic, change in time, properties, and dependence, will not beaddressed in this course. The free online StanfordEncyclopedia of Philosophy contains comprehensive, entry-level readable,overviews of such foundational issues.
4. Bottom-up ontology development
Bottom-up ontology development starts from the other end ofthe spectrum, where it may be that the process is at least informed byfoundational ontologies. Principally, one can distinguish between (i)transforming information or knowledge represented in one logic into an OWLspecies, (ii) transforming somewhat structured information into an OWL species,(iii) starting at the base. Practically, this means starting from some 'legacy'material (i.e., not-Semantic Web and, mostly, not-ontology), such as, but notlimited to:
1. Databases
2. Conceptual models (ER, UML)
3. Frame-based systems
4. OBO format
5. Thesauri
6. Biological models
7. Excel sheets
8. Tagging, folksonomies
9. Output of text mining, machine learning, clustering
Figure 5 gives an idea as to how far one has to 'travel'from the legacy representation to a 'Semantic Web compliant' one (and,correspondingly, put more effort into realize it).
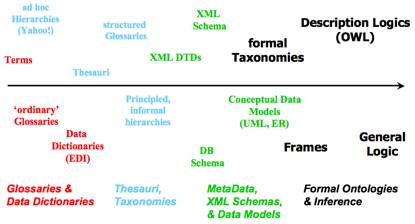
Figure 5. Various types of less and more comprehensivelyformalised 'legacy' resources.
Given the limited time available, we shall not discuss allvariants. Instead, we shall focus taking databases as source material,biological models, thesauri, and NLP.
4.1 Relational databases and related 'legacy' KR
Some rather informal points about reverseengineering from databases to ontologies will be structured briefly; a more formal account can befound in, e.g.,. In thebest situation, a first pass of reverse engineering a database schema resultsin one of the possible logical models (i.e., for RDBMSs, the relational model),another pass brings one up to the conceptual data model (such as ER, ORM)[33],and then one can commence with the ontological analysis and conversion to asuitable logic language (in this setting: an OWL species). Among others, the Object Management Group's Ontologydefinition metamodel is exploring interactions between UML and OWL &RDF.
Imperfect transformations from other languages, such as thecommon OBO format and a pure frames-based approach[35],are available as well, which also describe the challenges to create them. Whilethe latter two do serve a user base, their overall impact on widespreadbottom-up development is very likely to be less than the potential that mightpossibly be unlocked with leveraging knowledge of existing (relational)databases. One may be led to assume this holds, too, for text processing (NLP)as starting point for semi-automated ontology development, but the results havenot been very encouraging yet.
4.2 Natural language processing and ontologies
There is a lot to be said about how Ontology, ontologies,and natural language interact from a philosophical perspective up to the pointthat different commitments lead to different features and, moreover,limitations of a (Semantic Web) application.In this lecture, however, more emphasis will be put on the interaction of NLPand ontologies from an engineering perspective.
Natural language processing (NLP) can be useful for ontologydevelopment, it can be used as a component in an ontology-driven informationsystem and an NLP application can be enhanced with an ontology. Whichapproaches and tools suit best depends on the goal (and background) of itsdevelopers and prospective users, ontological commitment, and availableresources.
Summarising the possibilities for "something natural languagetext" and ontologies or ontology-like artifacts, we can:
- Use ontologies to improve NLP: to enhance precision and recall of queries (including enhancing dialogue systems), to sort results of an information retrieval query to the digital library (e.g. GoPubMed), or to navigate literature (which amounts to linked data).
- Use NLP to develop ontologies (TBox): mainly to search for candidate terms and relations, which is part of the suite of techniques called 'ontology learning'.
- Use NLP to populate ontologies with instances (ABox): e.g., document retrieval enhanced by lexicalised ontologies and biomedical text mining [pdf].
- Use it for natural language generation (NLG) from a formal language: this can be done using a template-based approach that works quite well for English but much less so for grammatically more structured languages such as Italian, or with a full-fledged grammar engine as with the Attempto Controlled English and bi-directional mappings (see for a discussion).
Intuitively, one may be led to think that simply taking thegeneric NLP or NLG tools will do fine also for the bio(medical) domain. Any applicationdoes indeed use those techniques and tools—Paul Buitelaar's slides have examplesand many references to NLP tools—but, generally, they do not sufficeto obtain 'acceptable' results. Domain specific peculiarities are many andwide-ranging. For instance, to deal with the variations of terms (scientificname, variant, common misspellings) and the grounding step (linking a term toan entity in a biological database) in the ontology-NLP preparation andinstance classification side , to characterize the question in aquestion answering system correctly (e.g., ), and to find ways to dealwith the rather long strings that denote a biological entity or concept oruniversal . Some of such peculiarities actually generate better overallresults than in generic or other domain-specific usages of NLP tools, but itrequires extra manual preparatory work and a basic understanding of the subjectdomain and its applications.
4.3 Biological models and thesauri
Two examples that, by basic idea at least, can have a largeimpact on domain ontology development will be described during the lecture:taking biological models (or any other structured graphical representation) asbasis[44]—whichamounts to formalizing the graphical vocabulary in textbooks and drawingtools—and the rather more cumbersome one of sorting out thesauri[45],[46],which faces problems such as what to do with its basic notions (e.g., "RT:related term") in a more expressive OWL ontology. Both examples have abundantsimilar instances in science, medicine, industry, and government, and,undoubtedly, some more automation to realize it would be a welcome addition toease the efforts to realize the Semantic Web.
5. Methods and methodologies
The previous lectures have given you a basic idea about thetwo principal approaches for starting to develop an ontology—top-down andbottom-up—but they do not constitute an encompassing methodology to develop them. In fact, there is no proper,up-to-date comprehensive methodology for ontology development like there is forconceptual model development (e.g., Halpin)or 'waterfall' versus 'agile' software development methodologies. There aremany methods and, among others,the W3C's Semantic Web bestpractices, though, which to a greater or lesser extent can form part of acomprehensive ontology development methodology.
5.1 Design parameters and their dependencies
Ontology development methodologies provide scenarios, butthey do not address the dependencies between the permutations at the differentstages in the development process. As a first step towards methodologies thatgives a general scope, we will look at a range of parameters that affectontology development in one way or another.The parameters considered are: nine main purpose(s) of the ontology, reuse ofthe three main types of ontologies, eight different ways for bottom-up ontologydevelopment, eight ontology languages, and four types of reasoning services.All dependencies between these parameters have been assessed, such as whichpurpose necessarily limits one to a given language, and useful combinations aremotivated. Thedependencies are due to, primarily, computational challenges and types andsubject domain of the ontologies. This analysis is assessed against a set ofontologies and a survey among ontology developers, whose results concur withthe theoretical assessment.
5.2 Methods: OntoClean and Debugging
Methods that help the ontologist in certain tasks of theontology engineering process include, but are not limited to, assisting themodelling itself, how to integrate ontologies, and supporting software tools.We will take a closer look at OntoClean[50]that contributes to modelling taxonomies. One might ask oneself: who cares,after all we have the reasoner to classify our taxonomy anyway, right? Indeed,but that works only if you have declared many properties for the classes, whichis not always the case, and the reasoner sorts out the logical issues, but notthe ontological issues. OntoClean usesseveral notions from philosophy, such as rigidity, identity criteria, and unity[51],[52]to provide modelling guidelines. For instance, that anti-rigid propertiescannot subsume rigid properties; e.g., if we have, say, both Student and Person in our ontology, the former is subsumed by thelatter. The lecture will go into some detail of OntoClean.
If, on the other hand, you do have a rich ontology and notmostly a bare taxonomy, 'debugging' by availing of an automated reasoner isuseful in particular with larger ontologies and ontologies represented in an expressiveontology language. Such 'debugging' goes under terms like glass box reasoning[53],justification,explanation, andpinpointing errors. While they are useful topics, we will spend comparativelylittle time on it, because it requires some more knowledge of DescriptionLogics and its (mostly tableaux-based) reasoning algorithms. Those techniquesuse the automated reasoner to at least locate modelling errors and explain in the most succinct way why this is so, instead of just returning a bunch ofinconsistent classes; proposingpossible fixes is yet a step further.
5.3 Methodologies and tools
Aside from parameters, methods, and tools, there are onlyfew methodologies, which are even coarse-grained: they do not (yet) contain allthe permutations at each step, i.e., whatand how to do each step, giventhe recent developments. A comparatively comprehensive methodology is Methontology[56],which has been applied to various subject domains since its development in thelate 1990s (e.g., the chemicalsand legal domain). Whilesome practicalities are superseded with more recent[59]and even newer languages, tools, and methodologies[60],some of the core aspects still hold. The five main steps are: specification,conceptualization (with intermediate representations, such as in text or diagrams, like with Object-RoleModeling and pursued by the MOdelling wiKI MOKIthat was developed during the APOSDLEproject for work-integrated learning),formalization, implementation, and maintenance. Then there are varioussupporting tasks, such as documentation and version control.
Last, but not least, there are many tools around that helpyou with one method or another. WebODEaims to support Methontology, the NeOn toolkit aims to supportdistributed development of ontologies, RacerPlus forsophisticated querying, Protégé-PROMPTfor ontology integration (there are manyother plug-ins for Protégé), SWOOGLEto search across ontologies, OntoCleanwith Protégé, and so on and so forth. For much longer listings of tools,see the list of semantic webdevelopment tools [html] (updated), the plethora ofontology reasonersand editors, and range of semantic wikiprojects engines and features for collaborative ontology development.Finding the right tool to solve the problem at hand (if it exists) is a skillof its own and it is a necessary one to find a feasible solution to the problemat hand. From a technologies viewpoint, the more you know about the goals,features, strengths, and weaknesses of available tools (and have the creativityto develop new ones, if needed), the higher the likelihood you bring apotential solution of a problem to successful completion.
6. Extra topics
There are many topics in ontology engineering that deserveattention, which range form foundational issues, to engineering solely in thescope of the Semantic Web, to application areas with respect to peculiaritiesof a particular subject domain. For instance, ontology matching and alignment[62]has a 'long' history (since the mid-1990s)whereas modularization is a current hot topic with a flurry of recent papers[64],the interaction of ontology with conceptual data models and reasoning shouldbe, and work toward temporal ontologies is on the rise, whereas the socialdimension of ontology engineering is inherent in the endeavour. Here I willbriefly describe some of these topics, of which we can choose one, depending onthe interest of the participants and remaining time available.
6.1 Uncertainty and vagueness
This advanced ontology engineering topic concerns how tocope with uncertainty and vagueness in ontology languages and theirreasoners—and what we can gain from all the extra effort. At the time ofwriting, this elective topic is mainly focused on theory and research.
Consider, for instance, information retrieval: to which degree is a web site, a page, a text passage, an image, ora video segment relevant to the information need and an acceptable answer towhat the user was searching for? Or in the context of ontology alignment, onewould want to know (automatically) to which degree the focal concepts of two or more ontologiesrepresent the same thing, or are sufficiently overlapping. In an electronic health record system,one may want to classify patients based on their symptoms, such as throwing up often, having a high blood pressure, and yellowish eye colour. How can software agents do the negotiation for yourholiday travel plans that are specified imprecisely, alike "I am looking for apackage holiday of preferably less than 1000 euro, but really no more that 1150 euro, for about 12 days in a warm country"?
The main problem to solve, then, is what and how toincorporate such vague or uncertain knowledge in OWL and its reasoners. To clarify thesetwo terms upfront:
- Uncertainty: statements are true or false, but due to lack of knowledge we can only estimate to which probability / possibility / necessity degree they are true or false;
- Vagueness: statements involve concepts for which there is no exact definition (such as tall, small, close, far, cheap, expensive), which are then true to some degree, taken from a truth space.
The two principal approaches regarding uncertainty and theSemantic Web are probabilistic and possibilistic languages, ontologies, andreasoning services, where the former way of dealing with uncertainty receives alot more attention than the latter. The two principal approaches regardingvagueness and the semantic web are fuzzy and rough extensions, where fuzzyreceives a lot more attention compared to the rough approach. The lecture willcover all four approaches to a greater (probabilistic, fuzzy) and lesser(possibilistic, rough) extent.
None of the extant languages and automated reasoners thatcan cope with vague or uncertain knowledge have made it into mainstreamSemantic Web tools yet. There was a W3C incubator group onuncertainty, but it remained at that. This has not stopped research in thisarea; on the contrary. There are two principle strands in these endeavours: onewith respect to extending DL languages and its reasoners, such as Pronto that combines the Pelletreasoner with a probabilistic extension and FuzzyDLthat is a reasoner for fuzzy SHIF(D),and another strand that uses different techniques underneath OWL, such asBayesian networks for probabilistic ontologies (e.g., PR-OWL), and Mixed Integer Logic Programmingfor fuzzy ontologies. Within the former approach, one can make a furtherdistinction between extensions of tableaux algorithms and rewritings to anon-uncertain/non-vague standard OWL language so that one of the generic DLreasoners can be used. For each of these branches, there are differences as towhich aspects of probabilistic/possibilistic/fuzzy/rough are actually included.
We shall not cover all such permutations in the lecture, butinstead focus on general aspects of the languages and tools. A goodintroductory overview can be found in(which also has a very long list of references to start delving into the topics(you may skip the DLP section)). Depending on your background education, you may find the more technicaloverview useful aswell. To get an idea of one of the more recent results on rough DL-basedontologies, you might want to glance over the theory and experimentation[67],[68].Last, I assume you have a basic knowledge of probability theory and fuzzy sets;if there are many people who do not, I will adjust the lecture somewhat, butyou are warmly advised to look it up before the lecture if you do not knowabout it (even if it is only the respective Wikipedia entry).
6.2 Time and Temporal Ontologies
There are requests for including a temporal dimension inOWL; for instance, you can check the annotations in the OWL files of BFO andDOLCE (or, more conveniently, search for "time" in the pdf)where they mention temporality that cannot be represented in OWL, or SNOMED CT's concepts like "Biopsy, planned" and "Concussion with loss of consciousness forless than one hour" where the loss ofconsciousness still can be before or after the concussion, or a business rulealike 'RentalCar must be returned before Deposit is reimbursed' or the symptom HairLoss during the treatment Chemotherapy, and Butterfly is a transformationof Caterpillar.
Unfortunately, there is no single (computational) solutionto address all these examples at once. Thus far, it is a bit of a patchwork,with, among many aspects, the Allen's interval algebra (qualitative temporalrelations, such as before, during, etc.),Linear Temporal Logics (LTL), and Computational Tree Logics (CTL, withbranching time), and a W3C Working draft of a time ontology.
If one assumes that recent advances in temporal DescriptionLogics may have the highest chance of making it into a temporal OWL(tOWL)—although there are no proof-of-concept temporal DL modelling toolsor reasoners yet—then the following is 'on offer'. A very expressive(undecidable) DL language is DLRus (with the until and sinceoperators), which already has been used for temporal conceptual data modelling[69]and for representing essential and immutable parts and wholes[70].A much simpler language is TDL-Lite,which is a member of the DL-Lite family of DL languages of which one is thebasis for OWL 2 QL; but these first results are theoretical, hence no "litetOWL" yet. It is already known that EL++ (the basis for OWL 2 EL) does not keepthe nice computational properties when extended with LTL, and results with EL++with CTL are not out yet. If you are really interested in the topic, you maywant to have a look at a recent surveyor take a broader scope with any of the four chapters from the KR handbook[73](that cover temporal KR&R, situation calculus, event calculus, and temporalaction logics), and severalpeople with the KRDB Research Centre work on temporal knowledgerepresentation & reasoning. Depending on the remaining time during the lecture, more or less abouttime and temporal ontologies will pass the revue.
6.3 Challenges in representation and reasoning over ontologies and socialaspects
The challenges for Semantic Web Technologies (SWT) ingeneral (and for bio-ontologies in particular) are quite diverse, of which someconcern the SWT proper and others are by its designers—and W3C coreactivities on standardization—considered outside their responsibility butstill need to be done. Currently, for the software aspects, the onus is put onthe software developers and industry to pick up on the proof-of-concept andworking-prototype tools that have come out of academia and to transform theminto the industry-grade quality that a widespread adoption of SWT requires.Although this aspect should not be ignored, we shall focus on the language andreasoning limitations during the lecture.
In addition to the language and corresponding reasoninglimitations that passed the revue in the lectures on OWL, there are languagelimitations discussed and illustrated at length in various papers, with themost recent take by Schulz and co-authors,where it might well be that extensions like the ones about uncertainty,vagueness and time can ameliorate or perhaps even solve the problem. Some ofthe issues outlined by Schultz and coauthors are modelling pitfalls, whereasothers are real challenges that can be approximated to a greater or lesserextent. We shall look at several representation issues that go beyond theearlier examples of SNOMED CT's "brain concussion without loss ofconsciousness"; e.g. how would you represent in an ontology that in most butnot all cases hepatitis has as symptomfever, or how would you formalize the defined concept "Drug abuse prevention", and (provided you are convinced it should berepresented in an ontology) that the world-wide prevalence of diabetes mellitus is 2.8%? One has to note, however, the initial outcome of asurvey conducted with ontology developers:there were discrepancies between the language features that were actually usedin the ontology and the perceived requirements for language features selectedby the survey respondents. This goes in both directions, i.e., where morefeatures were requested than have been used in the ontology they were involvedin and more features were used than were requested. Given that selecting anontology language is important for all four other design parameters, itdeserves further investigation how to overcome this mismatch.
Concerning challenges for automated reasoning, we shall lookat two of the nine identified required reasoning scenarios[76],being the "model checking (violation)" and "finding gaps in an ontology anddiscovering new relations", thereby reiterating that it is the life scientists'high-level goal-driven approach and desire to use OWL ontologies with reasoningservices to, ultimately, discover novel information about nature. You might find it of interest to read about the feedbackreceived from the SWT developers upon presenting that paper: some requirementsare met in the meantime and new useful reasoning services were presented.
Some of these issues also have to do with the tensionbetween the "montagues" and the "capulets". That is, social aspects, which arelightly described in,which is a write-up of Goble's presentation about the montagues and capuletsat the SOFG'04 meeting. It argues that thereare, mostly, three different types of people within the SWLS arena (it may justas well be applicable to another subject domain if they were to experiment withSWT, e.g., in public administration): the AI researchers, the philosophers, andthe IT-savvy domain experts. They each have their own motivations and goals,which, at times, clash, but with conversation, respect, understanding, compromise,and collaboration, one will, and can, achieve the realisation of theory andideas in useful applications.
Bibliography
A. Books and journals about ontologies
This is a selection of books on ontologies that focus ondifferent aspects of the endeavour; more books are on sale that specialize in aspecific subtopic. However, they are generally specialized books presentingrelatively new research, or handbooks at best, but none of them is a realtextbook (be they suitable for self-study or not).
Ontology and Ontologies
Steffen Staab and Rudi Studer (Eds.). Handbookon ontologies. 2009.
Zalta (Ed.). StanfordEncyclopedia of Philosophy. 2010.
Ontology Engineering
Gomez-Perez, A., Fernandez-Lopez, M., Corcho, O. OntologicalEngineering. Springer Verlag LondonLtd. 2004.
Ontologies in specific subject domains
Baker, C.J.O., Cheung, H. (Eds). SemanticWeb: revolutionizing knowledge discovery in the life sciences. Springer: New York, 2007, 225-248.
Semantic Web Technologies
Pascal Hitzler, Markus Kroetzsch, Sebastian Rudolph. Foundationsof Semantic Web Technologies. Chapman& Hall/CRC, 2009, 455p.
Various subtopics in ontologies
Jerome Euzenat and Pavel Shvaiko. OntologyMatching. Springer. 2007.
Heiner Stuckenschmidt, Christine Parent, StefanoSpaccapietra (Eds.). ModularOntologies—Concepts, Theories and Techniques for Knowledge Modularization. Springer. 2009.
Chu-ren Huang, Nicoletta Calzolari, Aldo Gangemi, AlessandroLenci, Alessandro Oltramari, Laurent Prevot (Eds.). Ontology and the lexicon. Cambridge University Press.2010.
General background material
Frank van Harmelen, Vladimir Lifschitz and Bruce Porter(Eds.). Handbookof Knowledge Representation. Elsevier,2008, 1034p.
Hedman, S. (2004). Afirst course in logic—an introduction to model theory, proof theory,computability, and complexity. Oxford:Oxford University Press.
F.Baader, D. Calvanese, D. L. McGuinness, D. Nardi, and P. F. Patel-Schneider(Eds). TheDescription Logics Handbook – Theory and Applications. Cambridge University Press, 2003.
J.E. Hopcroft, R. Motwani, and J. D. Ullman. Introductionto Automata Theory, Languages, and Computation. Pearson Education, 2nd ed., 2001.
Halpin, T., Morgan, T. Informationmodeling and relational databases. 2ndEd. Morgan Kaufmann. 2008.
Selection of journals that publish papers aboutontologies
B. Course References