Spellcheckers for isiZulu and isiXhosa
Overview - outputs and and download - participants
Overview
Spellcheckers for the most widely-spoken languages in the world are ubiquitous, from having them intergrated in text processing software, browsers, email software, and smartphones, among others. This is much less so for under-resourced languages, yet also speakers of such languages would want one. What got our efforts to develop spellcheckers for isiZulu off the ground was an explicit user request (from UKZN's ULPDO).There are several ways to develop a spellchecker for a language: encode the rules of its writing (ortography), using a dictionary, or learn a language model from lots of text (a corpus). Using a dictionary in the case of an agglutinating language is a non-starter, but we tried the other two approaches. The rules work better for those types of words (POS categories) covered in the rules than the statistical approach, but we have only a subset of those rules. Currently, the two released spellcheckers both use the data-driven approach.
The data-driven approach is illustrated in the following figure. First, there are the words in the corpus (just 4 in the example, but effectively, one needs at least some 20000 words of modern-day texts and preferable some 300 000). Second, the words are split up into trigrams. Third, a language model is computed from the trigrams: how often the trigram appears in the corpus compared to the other trigrams, where the uncommon ones are discarded are noise. Fourth, when a word is fed into the error detection algorithm, it splits up that word into trigrams and checks whether each one is sufficiently common; if so, then the word is porbably spelled correctly (e.g., ngihamba and ngivela in the figure), if not, then it is probably spelled incorrectly and flagged as such (gnihamba and ngivea).
For error correction, we use the same language model and some other statistics, like how probable it is that one trigram follows another, the levenshtein distance, and a list of words that were common in the corpus.
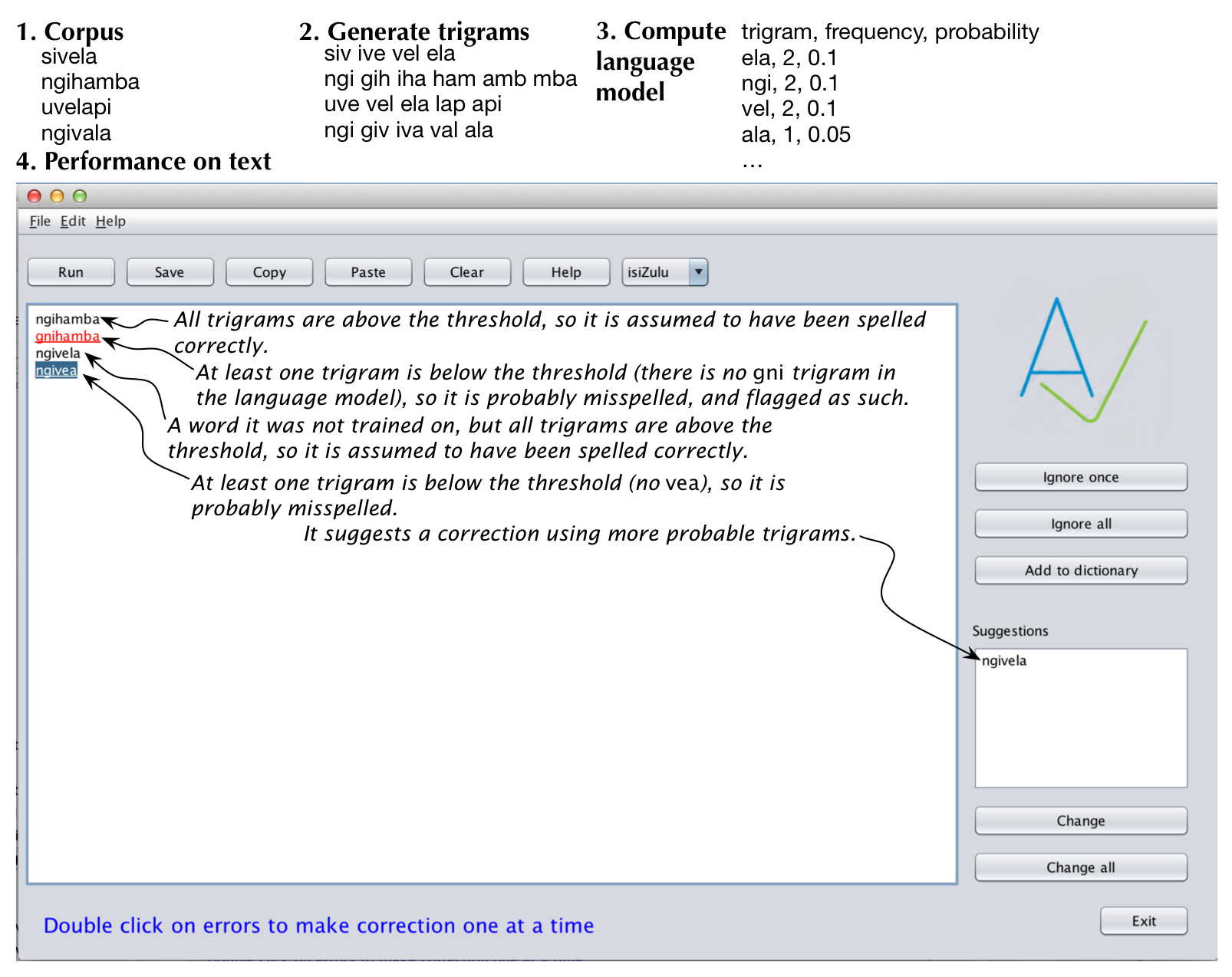
Here's a screenshot with some actual text and the performance on it. Overall, testing showed that accuracy and recall are around 90%. It also suggests several corrections, which works well especially for transpositions (two adjacent letters swapped). Note that both the detector and corrector only consider so-called non-word errors where a single character is misspelt.
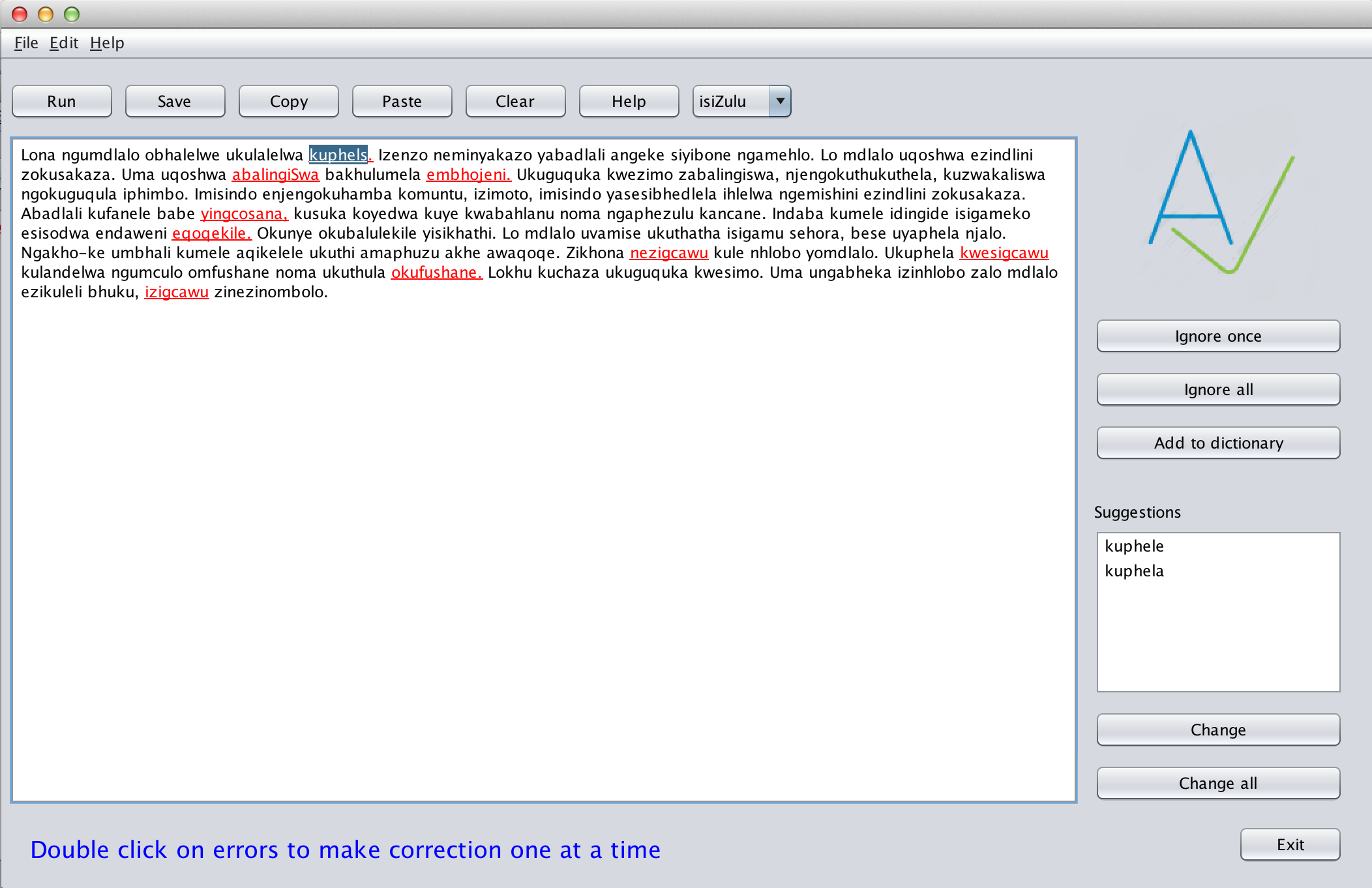
Other features of the tool are, among others, copy-paste of text, opening and saving files (txt or MS Word), and adding a word to your spellchecker installation's dictionary. You can switch between isiZulu or isiXhosa with the drop-down menu.
We know that a standalone jar file (that requires JDK) is not optimal, but integrating it with existing tools (browsers, text processing software) proved harder than it sounds for various reasons. So, for the time being, it is still this option.
For what it is worth it: we did evaluate v1 of the spellchecker, and users apparently liked it sufficiently and it turned out to contribute to intellectualisation of isiZulu.
There probably will be a v3 in the future, as there are several intersting 'loose ends' that we know of already. If you have any comments or suggestions, please contact us.
Outputs and download
- Publications
- Mjaria, F., Keet, C.M. A statistical approach to error correction for isiZulu spellcheckers. IST-Africa 2018, 9-11 May, Botswana. (accepted) experiment data
- Keet, C.M., Khumalo, L. Evaluation of the effects of a spellchecker on the intellectualization of isiZulu. Alternation, 2017, 24(2): 75-97.
- Ndaba, B., Suleman, H., Keet, C.M., Khumalo, L. The Effects of a Corpus on isiZulu Spellcheckers based on N-grams. IST-Africa 2016. Paul Cunningham and Miriam Cunningham (Eds). IIMC International Information Management Corporation. May 11-13, 2016, Durban, South Africa.
- Tools and source code
- Download the tool (v2)
- Source code of the isiZulu spelling corrector with improved ranking (not included in the v2 release)
- Source code spellchecker v2 of December 2017
- Download the tool (v1)
- Source code spellchecker v1 of November 2016
- Blog posts
- ICTs for South Africa's indigenous languages should be a national imperative, too, March 8, 2018
- Updated isiZulu spellchecker and new isiXhosa spellchecker, February 18, 2018
- The isiZulu spellchecker seems to contribute to 'intellectualization' of isiZulu, Dec 20, 2017
- Launch of the isiZulu spellchecker, November 11, 2016
- Preliminary promising results on a data-driven spellchecker for isiZulu, May 12, 2016
Participants, collaborators, contributors
- Maria Keet, Department of Computer Science, University of Cape Town (UCT)
- Hussein Suleman, Department of Computer Science, UCT
- Mantoa Smouse, African Languages and Literatures Section, UCT
- Former BSc(honours) students who contributed to the spellchechers at CS@UCT, as CS hounours projects: Frida Mjaria, Siseko Neti, Nthabiseng Mashiane, Balone Ndaba, Victor Kabine
- Programmer: Norman Pilusa, Department of Computer Science, UCT
- Langa Khumalo, Linguistics Program, School of Arts, University of KwaZulu-Natal